Introducing LaserData Cloud Free Tier
The story behind LaserData, why we built it on Apache Iggy, and why we believe real-time and agentic systems need a new kind of data plane.


A little over three years ago, Piotr made the first commits to what would eventually become Apache Iggy (Incubating). It began as a personal side project, with a simple goal: learn Rust by building something real. Streaming infrastructure became the project partly because Piotr had spent years running brokers in production and knew, firsthand, where the existing systems felt heavier and more complex than they needed to be.
Kranti’s obsession with ultra-low-latency, resource-efficient data infrastructure started earlier. While leading search, personalization, and real-time AI/ML workloads at Apple, he saw how every additional 50–100 milliseconds could affect customer experience and revenue. He also saw a familiar pattern: teams compensating for infrastructure limits by throwing more hardware at the problem. That experience made the need for a different kind of streaming platform feel obvious, and helped shape the belief that the next generation of data streaming systems should be built in Rust.
That shared conviction brought Kranti and Piotr together.
That side project grew. It picked up contributors, found early users, and became one of the top three Rust projects in the Apache GitHub organization by stars, with 4,200+ GitHub stars, a Discord community nearing 700 members, and well over 100 contributors. It also became something many teams started reaching out about: How do we run this in production without owning the platform team that keeps it healthy?
That question is the reason LaserData Cloud exists. Today, we are opening it up.
Why now
Three things have shifted at the same time, and together they make this the right moment to ship LaserData Cloud.
The first is workloads. Agents, retrieval pipelines, and real-time decision systems are pushing latency budgets that traditional streaming was never designed for. The tail is no longer a chart on a dashboard. It is the difference between an agent that feels instant and one that feels broken.
The second is hardware. Modern servers, NVMe gen4 and gen5, and userspace I/O primitives like io_uring have changed what is technically achievable per dollar and per watt. Brokers that cannot exploit this hardware leave most of the available performance unclaimed. Iggy was built specifically to claim it.
The third is open-core adoption. More than ever, teams want open infrastructure they can trust, but they also need a platform they can run in production, buy with confidence, and adopt without taking on another infrastructure tax. Open source creates trust. A managed platform creates leverage. Enterprises increasingly need both.
LaserData Cloud is the combination we wished existed back when we were running streaming systems at scale and could not find a platform that respected modern workloads, modern hardware, and modern open-source expectations all at once.
A faster engine deserves an easier operating model
If you have operated streaming infrastructure at scale, the failure modes are familiar. Tail latency that quietly destroys SLOs even when averages look fine. Operational complexity that grows faster than the team using it. Cost curves that turn an internal commitment to streaming into a quarterly review. A constant trade-off between performance, reliability, and engineering velocity.
Apache Iggy was built to address the engine half of this problem: hyper-efficient, predictable, latency-first, written in Rust on top of io_uring, with thread-per-core execution and zero-copy paths through the hot loop. Last year, the project was voted into the Apache Incubator, and that work now continues at Apache, on neutral ground, with open governance. Kranti led the effort to bring Iggy into the Apache Software Foundation because we wanted the engine to live where users and contributors could trust its future: in the open, with durable governance, not under a single vendor's control.
LaserData Cloud is the other half: a managed platform that runs Iggy as a service so engineering teams can use it without inheriting another piece of infrastructure to operate. The engine has to be honest about what it costs to run. The platform has to be honest about what it takes to operate. Both have to be true at once.
What launches today
The headline of this launch is access. The engine, the performance characteristics, and the architecture are already public and have been for a while. What changes today is that the platform is open, and there is a path for any team to start using it without a sales call:
- Free tier. A sandbox in AWS or GCP for evaluation, with no commitment.
- Fully managed deployments. We host and operate Iggy for you in our cloud, so you can focus on what you build on top of it.
- Bring Your Own Cloud (BYOC). The same managed experience, deployed into your own AWS or GCP account so data stays inside your perimeter and your existing cloud commitments.
- Storage that matches the workload. NVMe SSD for the lowest tail latency, or Network Drive for cost-flexible retention.
- Connectors at launch. Built-in Rust-native source connectors for PostgreSQL, Elasticsearch, InfluxDB, and Random, plus sink connectors for PostgreSQL, Elasticsearch, Apache Iceberg, Quickwit, MongoDB, InfluxDB, Delta Lake, HTTP, and Stdout. That covers operational databases, search, time-series, lakehouse, and debugging paths from day one.
- A modern operator experience through the LaserData Console and a single-binary CLI that works both headless and as an interactive TUI.
- Enterprise-grade controls, observability and security out of the box: RBAC, metrics, heartbeats, structured logs, audit, zero-trust architecture, scoped credentials, and a clean separation between the control and data planes.
Every deployment ships standalone today. Cluster mode is in initial preview and under active development: full high-availability for production-ready workloads, on top of the Viewstamped Replication consensus work happening upstream in Apache Iggy. Free tier remains standalone; the rest of the tiers are wired for cluster as soon as it lands.
Getting started
Getting onto the platform is intentionally short:
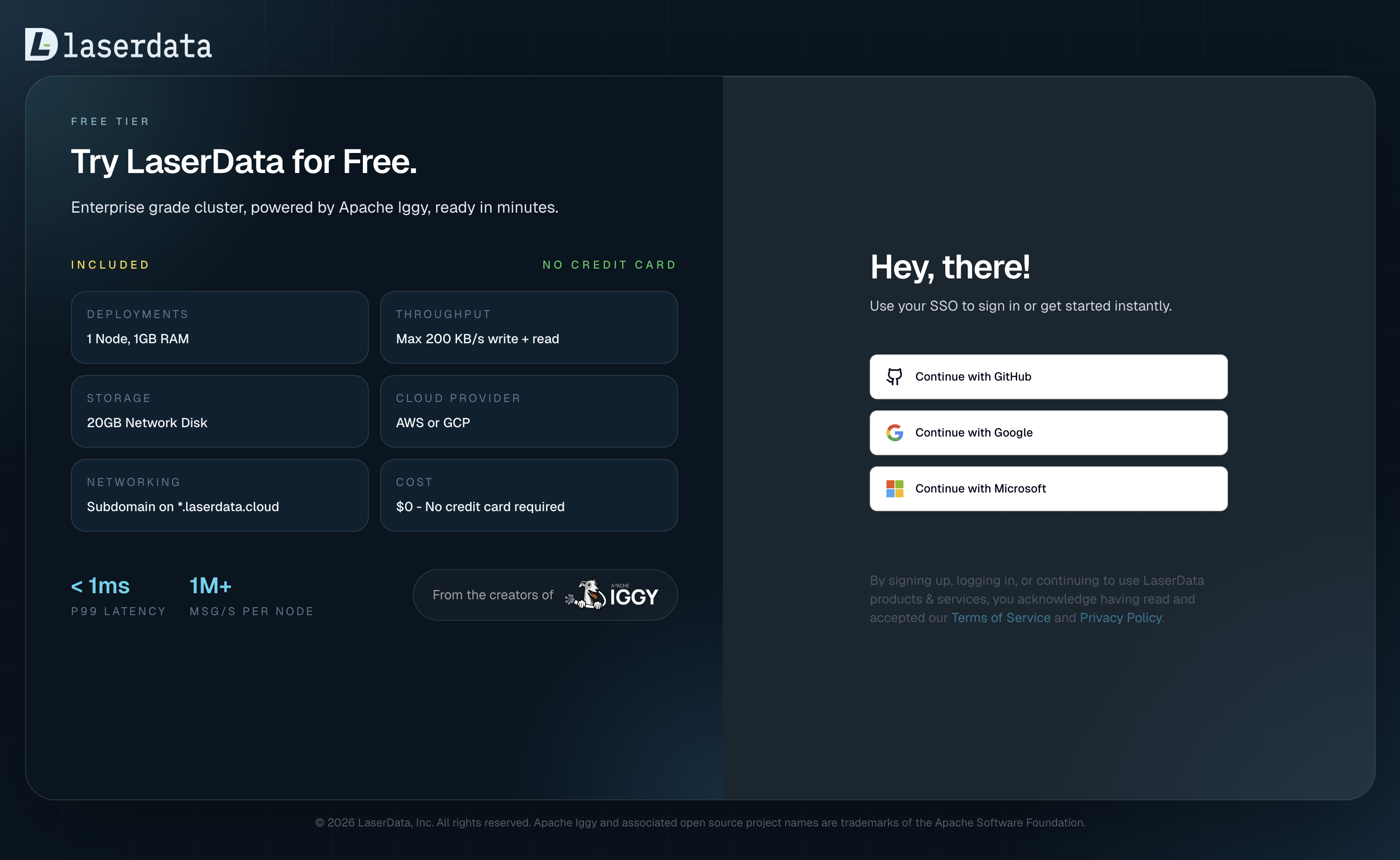
- Open laserdata.cloud and sign up through the SSO form.
- We activate your account on our side. You will get a notification when it is ready.
- Hit Quick Start on the organization dashboard, pick a region, and have your first free-tier deployment running in under three minutes. The visual walkthrough shows every screen of the flow.

On the client side, you connect using the official Apache Iggy SDKs. The SDK you use against a local Iggy server is the same SDK you use against a managed LaserData Cloud deployment, by design. Nothing about your client code changes when you move workloads onto the platform.
Full platform setup, configuration reference, and tutorials live at docs.laserdata.com.
A quick look at the platform
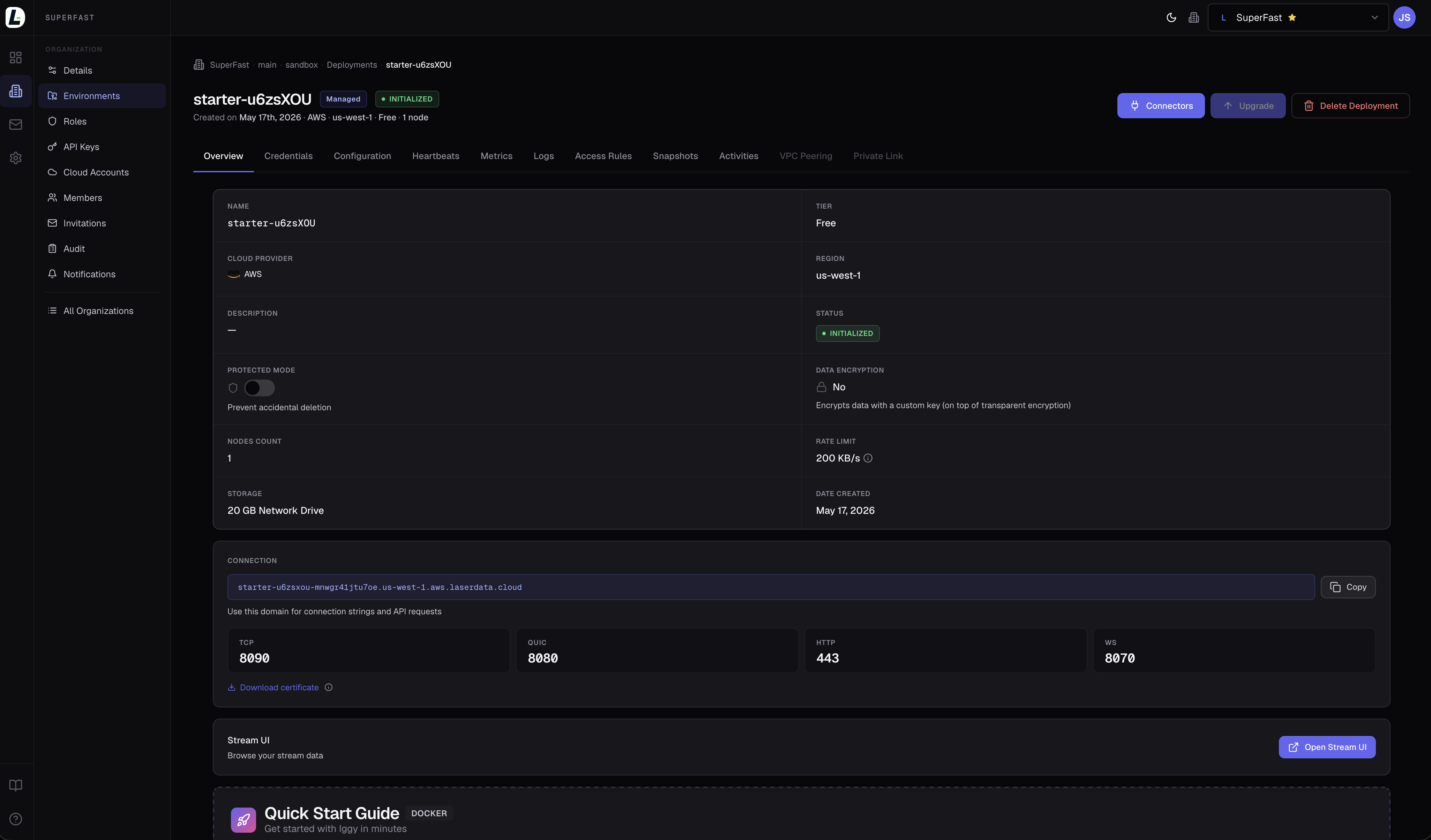
Every deployment exposes credentials, configuration, heartbeats, metrics, logs, access rules, snapshots, and audit in one place. VPC peering and Private Link are available on higher tiers.
Inside an account, resources live in a tenant, divisions, environments, deployments hierarchy, so you can mirror real organizational structure and isolate dev, staging, and production.
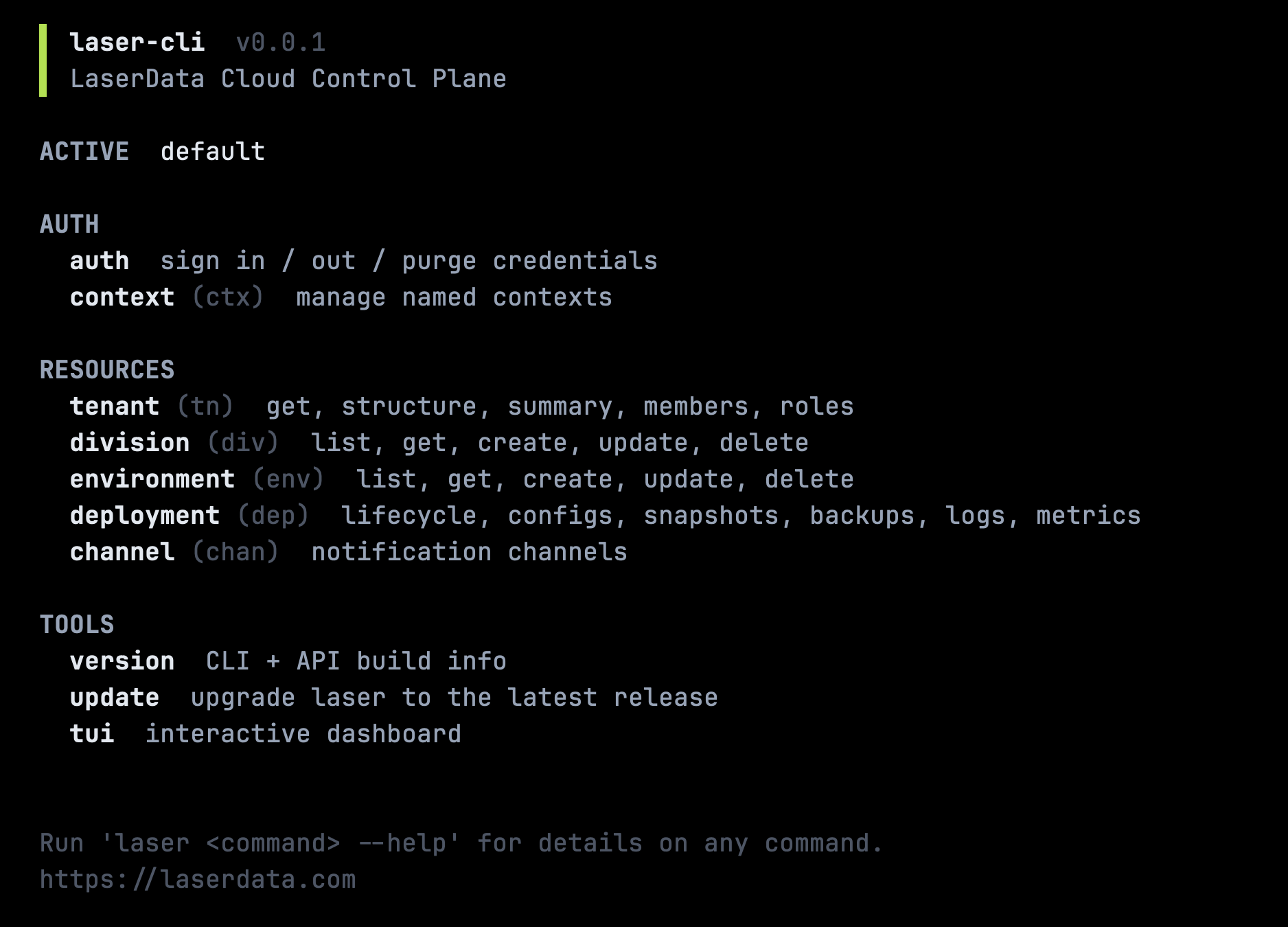
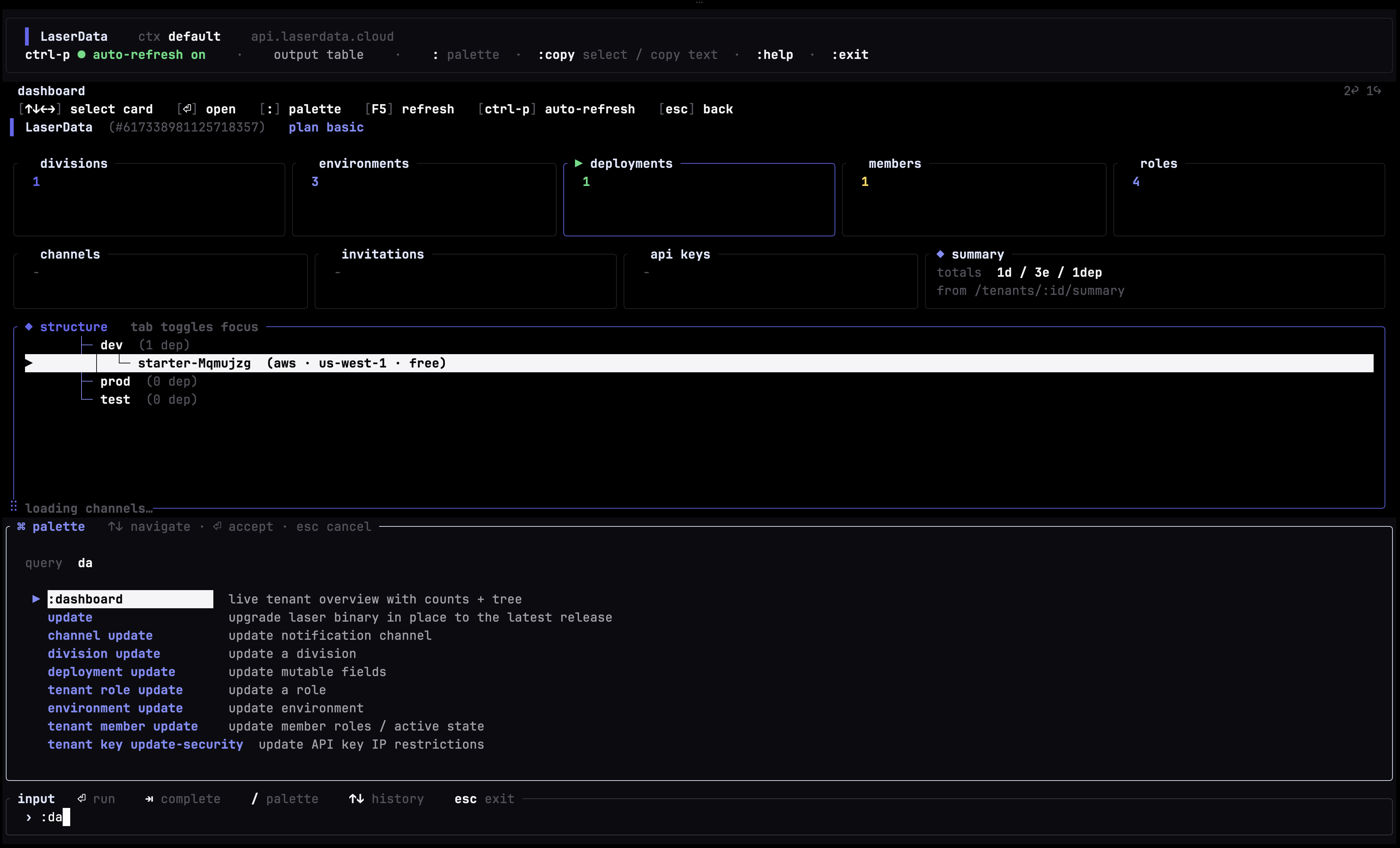
Alongside the Console, we ship laser-cli, a single binary that runs both headless (for automation, CI/CD, and scripting) and as an interactive TUI (for everyday operator work). Same backend, two front-ends, depending on whether you are scripting or exploring.
Install is one line, on Linux (x86_64 / arm64) and macOS (Apple Silicon):
$ curl -fsSL https://cli.laserdata.cloud/install.sh | shAppend --with-cc-skills to the install one-liner to bundle the official Claude Code skill pack (slash commands like /laser-deploy, /laser-troubleshoot) in the same step. Full command reference lives at docs.laserdata.com/cli.
How we plan to operate
We have opinions about how this should be built, and most of them come down to discipline:
Performance is a contract. Every latency number we publish is one we will reproduce in your environment, with your workload, under saturation. If we cannot defend it honestly, we will not claim it.
Operational complexity belongs in the platform, not on your team. The best feature is the one a customer never has to think about. We will not solve our internal problems by adding configuration surface area to yours.
Iggy stays at Apache, forever. Bringing Iggy to the Apache Software Foundation was a deliberate, long-term decision, not a marketing move. The streaming and infrastructure space has seen its share of overnight license changes, surprise relicensings, and projects pulled out of their foundations once open-source became inconvenient for the parent company. We never wanted that to be a possibility here. Apache governance is the strongest guarantee that the engine underneath your platform stays open, permissively licensed, and community-governed, with no overnight surprises. The clients you use against LaserData Cloud today are the official Apache Iggy SDKs, the same ones you would use against a local Iggy server.
Dedicated isolation, always. No shared VMs. No noisy neighbors. Every deployment, including Free tier, runs on its own VMs, with its own storage, on its own network path. We are not interested in margin tricks that show up later as someone else's spiky traffic on your data path.
Where something is in preview, we say so. Where a default is opinionated, we explain why. Where a trade-off exists, we name it. Documentation that survives contact with production engineers tends to look very different from documentation that does not.
Where we are going
The next generation of infrastructure will not be organized around batch windows and dashboards. It will be organized around software that continuously senses, decides, acts, and coordinates in real time. Agents will read live context, call tools, trigger workflows, write state, and hand work to other agents in loops where latency is no longer an optimization. It is part of the product.
That changes what a data plane has to be. It is not enough to move bytes durably from A to B. The substrate underneath AI systems has to preserve low tail latency under load, ingest context from the surrounding data stack, expose clean control surfaces, and support higher-level coordination patterns without forcing teams to assemble a fragile pile of brokers, connectors, queues, caches, and custom glue.
That is where we believe LaserData Cloud can lead. A fast managed streaming platform is the starting point. The real goal is the real-time backbone for agentic data infrastructure: a platform where it is natural to connect live enterprise data, move it with deterministic performance, and coordinate machine-driven workflows on one open, efficient substrate.
That direction is already beginning to show up upstream. Initial Agent-to-Agent (A2A) protocol support landed in Apache Iggy 0.8.0 as an early signal. Over time, we expect more of the primitives required by real-time, AI-native systems to belong directly in the data plane rather than as an afterthought around it.
The short version: General-purpose streaming is what we ship today. A more agent-aware data plane is what we are building on the same substrate.
What is next
This launch is the foundation. Over the coming months, you can expect:
- Cluster mode moving from preview to general availability, informed by real adoption.
- More connectors beyond the launch catalog, so streaming integrates naturally with databases, lakehouses, search, observability, and AI application stacks.
- More agent-aware platform primitives so AI systems can consume context, coordinate work, and act on live data without bespoke infrastructure.
- Deeper operator tooling across Console and CLI, with a strong bias toward boring infrastructure that just works.
- Continued engineering deep dives on this blog: how the platform is built, where the hard problems are, and what we are learning from customers.
If you are evaluating real-time streaming for AI workloads, modernizing an older broker, or considering LaserData Cloud for an upcoming initiative, we would like to hear from you. The fastest way is a short note to [email protected].
Thanks to the Apache Iggy community, our early adopters, and everyone who has helped shape this work over the last three years. The platform you can use today exists because of you.
Back to building. Welcome to LaserData Cloud.